



基于python的热映电影的影评数据爬虫分析 ——以豆瓣电影影评为例
摘要:本文使用Python网络爬虫技术对热映电影的影评数据进行爬取,包括伪装网络请求、导入网页链接、重复抓取过滤等,完成了以豆瓣电影影评为例的基于python的数据爬虫。通过数据可视化技术对获取的影评文本制作了词云,并对评论数变化、评论评分以及日期分布进行了展示。根据wordcloud模块对文本进行分词及关键字词云的生成,得到几个分类的主题词,清晰地呈现观众的情感倾向,直观地展示了电影上映后观众对电影的关注程度和观影感受,并能够进一步剖析平台评论的特性和内涵机器产生原因。
关键词:Python;网络爬虫;影评数据;数据分析
目录
第一章 引言 3
1.1研究背景 3
1.2 研究目的与意义 3
1.3 研究内容概述 4
第二章 主要相关技术介绍 5
2.1 Pycharm 5
2.2 SQL语言 5
2.3 MySQL数据库 5
2.4 Hadoop 6
第三章 需求分析 7
3.1 项目需求分析 7
3.2 用户需求分析 7
第四章 数据采集技术 9
4.1 网络爬虫简介 9
4.2 豆瓣电影网站及其影评数据 9
4.3 数据爬取过程 9
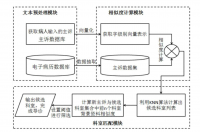
4.4数据解析与存储 12
4.4.1 平台的搭建 12
第五章 数据清洗 17
5.1 对数据进行清洗 17
第六章 数据可视化分析与展示 19
6.1可视化展示 19
6.2 可视化工具与技术选择 21
第七章 实验与结果 22
7.1 数据爬取与处理实验 22
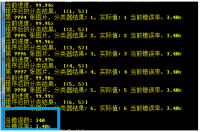
7.1.1 数据爬取 22
7.1.2 数据处理 23
7.2 数据可视化分析实验 25
7.2.1 数据准备 25
7.2.2 单变量分析 25
7.3 实验结果与分析 26
7.3.1 数据分析结果 26
7.3.2 结果解释与讨论 26
第八章 分析与讨论 28
8.1对电影的意义及需求与帮助 28
8.2 存在的问题与改进方向 29
8.2.1 数据采集的限制 29
8.2.2 数据处理与分析的局限性 29
致谢 31
参考文献 33
第一章 引言
1.1研究背景
国内电影市场增长迅速,中国已成为世界第二大电影市场,并在不断缩小与北美市场的差距,电影业迸发出强劲活力。如今,观众观看影视作品更加注重选择符合自己的价值观,电影制作有新意、有意义的电影,而不选择单纯博人眼球,利用流量明星赚取票房的电影。豆瓣电影作为中国最大的电影分享与评论社区,可提供最新的电影介绍及相关评论,并根据个人喜好,向用户推荐电影,同时,用户也可以根据电影的打分和影评选择是否观看一部电影,所以,对大量的影评数据进行深入分析,了解大众对电影的态度以及电影本身的特色,为观影者提供正确的导向是非常有意义的。在现在各种资源充斥的时代,有些电影人们一致认为他的质量有待提高,但是仍然会有少数的人选择去观看,利用网络数据爬虫,可获取到更加真实、全面的、有价值的数据信息。互联网的快速发展,迎来了一个关于大数据的崭新时代,每个人的一切都关乎着各种各样的数据,而且人们也越来越注重数据所带来的价值。如今,万维网已成为大量信息的有效载体,可是对有效信息的提取和利用却成为了一个巨大的挑战。利用网络爬虫技术,通过网站所允许的合法途径,我们可以方便快捷地获取到目标网页的数据,从而对获取到的数据进行分析研究,挖掘出数据背后的价值。
1.2 研究目的与意义
目的是深入探索豆瓣电影平台上的影评数据,分析影评数据的整体特征和趋势,并研究不同类型电影的受欢迎程度和评价差异。此外,旨在揭示观众对电影的情感反馈。
具有以下几个方面的意义和价值:
实践意义:豆瓣电影影评数据的可视化分析可以为电影从业者提供有关电影品质、观众喜好和评价趋势的深入洞察。基于本文研究的结果,可以制定更精准的市场营销策略、改进电影品质和满足观众需求,对电影产业的发展和市场竞争具有积极影响。
社会影响:为电影爱好者提供了一个新的角度去理解电影评价和观众反馈。可以借助研究的结果更好地选择、欣赏和分享电影作品。此外,市场研究人员可以通过深入洞察进行更准确的市场预测和决策制定,推动电影市场的发展和创新。
结合情感分析和数据可视化的方法,揭示观众对电影的情感反馈,包括喜欢、厌恶、激动等情感表达。有助于观众更准确地理解电影的情感色彩和情节吸引力,提高电影欣赏体验。
本文所使用的方法和技术,包括数据挖掘、情感分析和数据可视化,可为相关领域的研究和实践提供实证研究的范例和参考。同时,通过对豆瓣电影平台的案例研究,也为其他在线社交媒体平台和大规模用户生成内容的分析提供了一种方法和思路。
1.3 研究内容概述
以豆瓣电影平台为数据源,基于Python爬虫技术获取豆瓣电影影评数据,并进行数据清洗和预处理。接下来,将采用以下主要研究内容来实现对豆瓣电影影评数据的可视化分析:
数据统计与整体特征分析:首先,对豆瓣电影影评数据进行统计分析,包括评分分布、评论数量、观众人数等整体特征。通过数据可视化方法,绘制柱状图、折线图等形式,展示不同电影的评分分布情况和评论数量的变化趋势。
不同类型电影的评价比较:针对豆瓣电影上的不同电影类型,如剧情、喜剧、动作等,将进行评价比较分析。通过数据挖掘技术,提取不同类型电影的关键词和评价特点,并采用词云图、条形图等可视化方式,展示不同类型电影的受欢迎程度和评价差异。
情感分析与情感趋势分析将应用情感分析技术,对豆瓣电影影评数据进行情感分类和情感评分。通过对评论文本的情感倾向分析,揭示观众对电影的喜好、厌恶和激动等情感反馈。同时,还将通过情感趋势分析,探讨观众情感在不同时间段和电影类型之间的变化趋势,并采用折线图等方式进行可视化展示。
最后,将利用数据可视化工具和技术,将上述分析结果进行可视化展示。采用交互式可视化图表和界面,用户可以根据自己的兴趣和需求,动态探索不同电影的评价和观众反馈。同时,通过可视化呈现研究结果,更直观地展示豆瓣电影影评数据的特征和趋势,以及不同类型电影的评价比较和情感反馈分析。通过可视化图表和交互界面,用户可以深入了解电影评价的整体情况,比较不同类型电影的受欢迎程度和评价差异,探索观众的情感反馈和社交影响力。
第二章 主要相关技术介绍
2.1 Pycharm
PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
在本项目中,pycharm可以实现以下的功能:
1.数据处理与分析:该项目需要对大量的数据进行处理与分析,因此, PyCharm能够利用 Python中的模块以及第三方库,对诸如 pandas、 numpy、 matplotlib等数据进行处理与分析。
2. 数据清洗和存储:在将原始数据存储到csv和数据库之前,需要对其进行相应的清洗和处理,以保证后续存储的数据符合要求。将异常或者不符合要求的数据项的值进行筛选、删除或者修改。
3.数据可视化:在本项目中,需要将数据以图表的形式展现出来,通过PyCharm利用第三方库,比如 matplotlib、 seaborn等,来实现数据可视化。
2.2 SQL语言
SQL(“Structured Query Language”)是一种用于管理关系数据库的结构化查询语言,它的管理内容主要有数据的插入、查询、更新和删除,数据访问控制,建立、修改数据库架构等。SQL语言具有交互性的特点,可以给用户带来很大的便利,与此同时,SQL语言也可以单独使用在终端上,它还可以成为一种子语言,为其他程序设计提供了一种有效的帮助,在这个程序应用中,SQL能够与其他程序语言共同对程序的功能进行优化,从而为使用者提供更多更完整的信息。
2.3 MySQL数据库
MySQL是一种将数据保存在不同表中的关系型数据库管理系统,使速度大幅提升,灵活性提高,而不是全部放在一个大仓库里。它可以支持多个用户同时访问,也可以同时执行多个线程的数据库系统。MySQL数据库主要用来处理案例信息以及客户端发来的操作请求,保证存储数据的一致性和完整性,实现数据的共享与安全。
2.4 Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
MapReduce:MapReduce计算为程序员提供了两个简捷的编程接口,即Map函数和Reduce函数。任务的输入和输出数据按照Key-Value的方式组织,框架会自动将中间结果中相同Key值的记录聚合在一起,作为Reduce函数.
参考文献
[1]罗攀、蒋仟编著:《从零开始学Python网络爬虫》,机械工业大学出版社,2020年8月
[2]张涛编著:《从零开始学Scrapy网络爬虫》. 机械工业出版社. 2019年9月
[3]黄红梅、张良均、张凌、施兴、周东平著:《Python数据分析与应用》. 人民邮电出版社. 2018年4月
[4]RyanMichell著:《Python网络数据采集》. 人民邮电出版社 2016年3月
[5]胡松涛著:《Python网络爬虫实战》. 清华大学出版社 2018年9月
[6]杨健、陈伟著:《基于Python的三种网络爬虫技术研究》. 中国知网 2023年2月
[7]成文莹、李秀敏著:《基于Python的电影数据爬取与数据可视化分析研究》. 2019年11月
[8]汪言著:《基于Python的词云生成及优化研究————以“十四五”规划为例》. 2021年
[9]高璐、唐艳芳著:《基于Wordcloud技术的词云图实现》. 2021年12月
[10]辛雨璇,王晓东 . 基于文本挖掘的电影评论情感分析研究 [J]. 牡丹江师范学院学报(自然科学版),2021(1):25-28.
[11]高雨菲,毛红霞 . 基于 Python 的豆瓣影视短评的数据采 集与分析 [J]. 现代信息科技,2020,4(24):10-12+16.
[12]黄蓉,毛红霞 . 基于豆瓣网某系列电影数据采集与可视化 分析 [J]. 现代信息科技,2020,4(23):4-7.
[13]黄子豪,张舒 . 网络爬虫对互联网安全的影响及“反爬”策略的研究 [J]. 科学技术创新,2021(10):120-121.
[14]严明 , 郑昌兴 .Python 环境下的文本分词与词云制作 [J]. 现代计算机,2018(34):86-89.
[15]简悦,汪心瀛,杨明昕 . 基于 Python 的豆瓣网站数据爬 取与分析 [J]. 电脑知识与技术,2020,16(32):51-53.
,



